GraphRAG uses large language models (LLMs), guided by a set of domain-specific prompts, to create a comprehensive knowledge graph that details entities and their relationships and then uses semantic structure of the data to generate responses to complex queries.
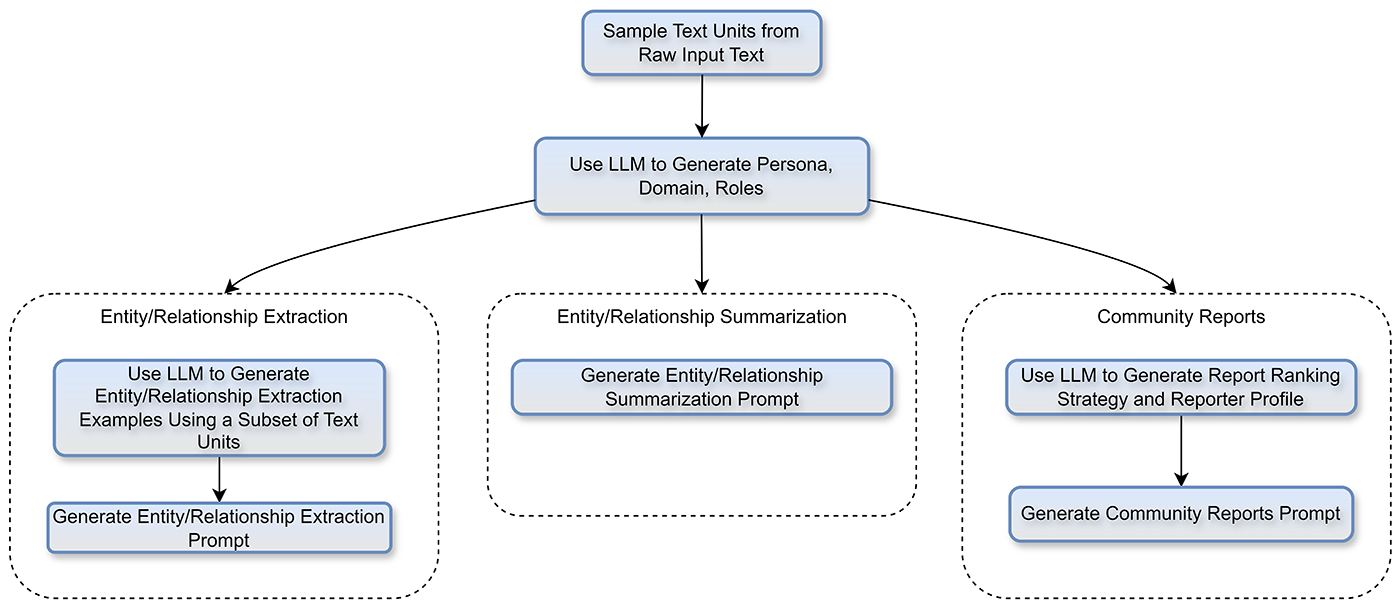
Manually creating and tuning such a set of domain-specific prompts is time-consuming. To streamline this process, researchers from Microsoft have developed an Auto-tuning tool in GraphRAG, which automated generation and fine tuning of domain-specific prompts.
Auto-tuning starts by sending a sample of the source content to the LLM, which first identifies the domain and then creates an appropriate persona—used with downstream agents to tune the extraction process. Once the domain and persona are established, several processes occur in parallel to create custom indexing prompts. This way, the few-shot prompts are generated based on the actual domain data and from the persona’s perspective.
Auto-tuning follows a human-like approach; provided an LLM with a sample of text data (e.g., 1% of 10,000 chemistry papers) and instructed it to produce the prompts it deemed most applicable to the content. Now, with these automatically generated and tuned prompts, one can immediately apply GraphRAG to a new domain of choosing, confident that we’ll get high-quality results.
Blog : GraphRAG auto tuning